





基于DA-BERT-CRF模型的古诗词地名自动识别研究——以金陵古诗词为例
文章来源:本站 发布者: 发布时间:2023-02-23 阅读:319 次
来源:
余馨玲 常娥
摘要
古诗词地名实体识别不仅有助于深度挖掘古诗词文本之间的关联,而且有助于绘制中国诗歌版图分布,推动空间维度的中国古典文学研究。文章围绕南京城系统采集有关古诗词数据,采用BIOES方法进行地名实体标注。针对古诗词领域训练数据匮乏、以字代词等问题,提出一种采用数据增强方法,同时融合预训练模型与条件随机场方法的古诗词地名识别模型,简称DA-BERT-CRF模型。文章将训练数据采用实体交叉互换方法进行数据增强处理,然后通过预训练模型BERT得到古诗词地名的上下文语义信息,最后利用条件随机场CRF实现地名标签约束并生成全局最优地名序列。文章提出的DA-BERT-CRF模型十折交叉实验平均精确率、平均召回率和平均F值分别为86.49%、90.44%、88.35%。
关键词
深度学习模型;地名实体识别;古诗词;数据增强
0 引言
近年来,人工智能领域深度学习算法的应用推动了“数智时代”的到来,“数智赋能”正成为图书情报领域发展新的生长点。我国图情领域早在20世纪末就开始关注并投身于古籍数字化建设实践中,经过近30年的发展已积累了丰厚的数字化古籍资源。然而这些数字化古籍资源大多属于非结构化数据,并未充分利用信息技术的巨大优势,实现古汉语文本的深度开发与“数智赋能”。利用自然语言处理、大数据分析、地理信息系统等技术,在古代典籍语料库上开展深层次的文本挖掘与知识发现研究,正伴随着数字人文和计算社会科学的发展而发挥着越来越大的学术价值,也是体现中国文化自信的重要途径。
四言诗经、五言古风、唐诗宋词蕴含了中国许多宝贵的传统文化,对古诗词进行命名实体识别,有助于挖掘以古诗词为代表的传统文化中包含的深层次知识概念。由于在历代古诗词中有很多围绕地名场所进行的描述与表达,例如北京、南京、西安、洛阳、杭州等,因而在漫长的历史岁月中,地名场所逐渐形成了一种文化符号,具有相对固定而独特的文化含义。识别出古诗词中的地名场所概念,不仅有助于深度挖掘古诗词文本之间的关联,而且有助于绘制中国诗歌版图分布,推动空间维度的中国古典文学研究,因此地名识别是古诗词文本挖掘的核心任务之一。过去围绕古诗词的地名注释与分析主要由人工来完成,然而传统人工方法信息处理效率低下,因此本研究致力于借助计算机技术,尤其是深度学习算法,探索古诗词地名自动识别的最佳模型。
1 国内外研究现状综述
命名实体识别(The Named Entity Recognition,以下简称NER)是自然语言处理的一项基础任务,其重要作用是从文本中准确地识别出人名、地名、机构名、事件、物品等信息。国外对于NER研究相对较早,1991年Rau等学者首次描述了一种从文本中提取公司名的方法,此后NER开始备受关注,并成为Text Retrieval Conference、Message Understanding Conference等一系列评测会议的核心主题。从20世纪90年代开始,传统NER方法主要是基于规则或统计的方法,如Bikel等人最早提出了基于隐马尔可夫模型(Hidden Markov Model,简称HMM)的英文NER方法,并讨论了训练数据集大小对于模型的影响。Ji-Hwan Kim提出了一种基于规则推理的NER方法,实验结果表明自动规则推理是基于HMM命名实体识别方法的可行替代方案。Borthwick最早提出了一种最大熵(Maximum Entropy,简称ME)NER方法,该方法的提出为诸多信息提取任务提供了新思路。尽管基于规则或统计方法在NER任务中取得了一定成功,但它们往往需要细致的人工操作和一定专业知识,因此NER效果很难取得大的突破。随着研究者不断进行深入研究,NER相关理论和方法愈加完善。2010年之后,深度神经网络学习方法兴起,其端到端的学习方式,使得机器能根据输入自动地发现对于目标任务有效的表示,因此NER又迎来了新的机遇和发展高峰,Collobert等人首次提出了一种基于神经网络架构的学习算法,该算法可以在大量几乎没有标记的训练数据基础上学习输入序列的内部表示,并可以应用于词性标注、NER等任务中。Lample等学者提出应用双向长短期记忆神经网络(Bi-directional Long Short-Term Memory,简称Bi-LSTM)和条件随机场模型(Conditional Random Field,简称CRF)的新型神经架构和基于转移方法进行构建和标记文本片段,该模型获得了最先进的NER性能。同时,随着深度学习算法日益成熟,不断崛起了许多新型NER技术,尤其2018年以来,以BERT(Bidirectional Enoceder Representations from Transformers)、GPT(Generative Pre-Training)为代表的深度学习模型更是帮助NER取得了一系列突破,如Lee提出一种在大规模生物医学语料库上预训练BioBERT模型,Eberts等人构建了一种跨度联合SpERT模型,与之前工作相比,模型F指标分别提高了0.62%和2.6%。
在国内,NER发展历程大致和国外一致,过去很长一段时间主要采用基于规则与词典方法,以及传统机器学习方法进行命名实体识别,诸如N元组法、CRF等。而中文语言特殊性决定了NER难度比英文难度大,例如中文文本的词语之间边界模糊,命名实体缺少明显词形变换特征等,基于规则的NER方法编制耗时且无法穷尽中文实体中出现的规则和模式,基于统计的NER方法对特征选取、语料库的要求和依赖较高。近年来,随着深度学习算法的兴起,使用诸如Bi-LSTM、BERT等深度学习模型处理中文NER问题成为一种趋势,并取得了显著效果。刘宇瀚等人从汉字自身特点出发,设计了结合字形特征、迭代学习以及Bi-LSTM和CRF的神经网络模型,该模型与最好的基线模型相比F指标提高了1.52%;王子牛等学者基于BERT模型对人民日报语料中实体进行识别,取得了94.86%的F值;刘新亮等人针对生鲜蛋供应链中领域实体提出BERT-CRF模型,模型F指标值达到91.01%。除了现代汉语文本外,古汉语NER工作同样引起了学者广泛关注,研究方法正由基于规则和统计的传统机器学习方法逐步转向深度学习模型。例如,早期朱锁玲等人采用规则与统计相结合的命名实体识别方法,F值为71.83%,黄水清等人以先秦典籍为研究语料,采用CRF模型实现了人名、地名和时间等实体自动识别。2018年以后,学者纷纷探索基于深度学习模型的NER方法,其中李成名将LSTM-CRF模型用于自动识别《左传》中的地名和人名,F值分别达到82.79%和82.49%;徐晨飞等人基于Bi-RNN、Bi-LSTM、Bi-LSTM-CRF和BERT这4种深度学习模型实现了《方志物产》的多类实体自动识别,F值最高达到89.70%,显示了深度学习模型在古汉语NER任务中的优越性。
我国古汉语NER技术不断发展与进步,但是古诗词地名实体识别研究仍在极少数,笔者仅查阅到一篇相关文献,崔竞烽等人利用Bi-LSTM、Bi-LSTM-CRF和BERT等模型实现了菊花古诗词语料中包含地名在内的多种实体识别研究。有鉴于此,本研究拟提出一种融合数据增强、预训练模型以及条件随机场方法的古诗词地名识别模型,简称DA-BERT-CRF模型,开展古诗词地名识别实验。
2古诗词地名实体库构建
2.1 古诗词原始语料采集与处理
古诗词是我国宝贵的历史文化遗产,种类复杂,按照内容可分为送别诗、借景抒情诗、托物言志诗等,数量多达百万首以上。考虑到本文致力于挖掘古诗词中的地名信息,因此尽可能地收集含有地名信息的古诗词,以更好地训练地名识别模型,提高识别效果。同时考虑到南京城历史悠久,历代文人墨客据此留下了诸多不朽诗词。故而本文主要围绕南京这一历史名城,系统采集相关古诗词作为实验语料以减少干扰数据。
金陵古诗词既包括诗人在南京创作描写南京的作品,又包括诗人在别处创作描写南京的作品,因此金陵古诗词的选择标准与古诗词作品中是否含有南京元素相关,与作品创作地、创作者无关。由于我国古诗词一般按照朝代、类别或诗人进行汇编整理,鲜有按照城市地域进行汇编整理,因此与南京相关的古诗词散落于各种古代诗歌总集、别集、合集,以及古代文学史等文献资源中。我国著名古诗词研究者王步高教授认为,与南京直接相关古诗词约1300多首,间接相关古诗词约1100多首。
本文主要通过两种数据源采集金陵古诗词:网站和图书。第一,通过Python语言,利用爬虫程序从古诗文网、搜韵网、诗词名句网等网站上,获取南京古诗词相关题目、作者、朝代及正文信息,将其以格式化形式存储在EXCEL文件中。第二,采用人工方式从《钟山诗文精选》(王步高编著)、《南京传》(叶兆言著)、《金陵旧事》(明.焦竑撰)等图书中采集并保存与南京古诗词相关题录及正文信息。通过这两种方式在采集与整理数据的过程中,本文发现了一些问题,对其进行了相应的处理:(1)古诗词重复:通过EXCEL中“删除重复项”将完全重复的诗词进行删除;(2)古诗词缺字:通过二次查找,查找权威图书文献进行人工补全;(3)古诗词内容相同,作者不同:通过查找专业图书文献,进行人工改正。最终本文获得金陵古诗词648首,共计57964个汉字,涉及的朝代包括魏晋、南北朝、唐、宋、元、明、清以及民国,其中唐宋诗词数量最多,占半数以上。
2.2 古诗词语料标注体系建立
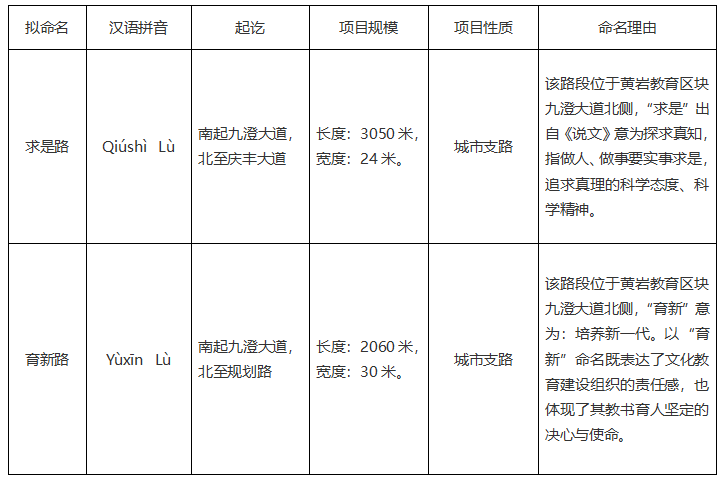
既有研究大多针对现代文本实体识别而生成语料库实体标注体系,目前尚未存在可直接利用的古诗词地名实体标注体系,本文主要参考百度百科、搜韵网以及知网文献对收集的648首金陵古诗词进行了4轮地名实体标注。标注方式采用BIOES标注集与Place结合的方式,B-Place代表实体的开始,I-Place代表实体的内部,E-Place代表实体的结尾,S-Place代表单字实体,O代表非实体,最后得到金陵古诗词标注体系数据集。例如唐代诗人李白创作的《洗脚亭》中诗句“西望白鹭洲”中“白鹭洲”是地名实体,便将其标注为“O,O,B-Place,I-Place,E-Place”,表1为标注集样例。
2.3 古诗词地名实体统计分析
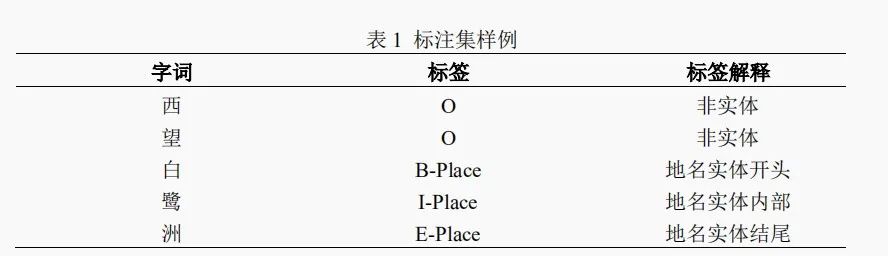
金陵古诗词地名实体标注结束后,本文对实体标注结果进行统计分析发现,648首古诗词中地点实体共出现1375次,实体的字符长度普遍介于2-3个字,存在字符长度为1和4的地名实体,如地点实体“淮”和地点实体“八功德水”,出现次数最多的是“金陵”,其次“钟山”、“台城”、“江南”,其中“金陵”的别称最多,有“建康”、“秣陵”、“建邺”、“南都”等。表2列出了金陵古诗词中出现频率前十的地点实体。
3 古诗词地名实体识别模型构建
3.1 古诗词地名实体识别特点分析
作为中国传统文化的古诗词无论是结构句式还是语法词藻都与现代文本,抑或是普通古汉语文本有着较大区别,深入分析古诗词地名实体特点发现存在以下几个特征:
特征1:古诗词中词藻讲究精简凝练,一般一个汉字都可能是一个兼具形、音、义的独立单位,因此古诗词中存在着以字代词的单字地名实体,如《采桑》(唐.郑谷)中诗句“采桑路隔淮”中的单字“淮”便代表“淮水”这一地点实体。故本文在深度学习模型特征向量的构建中,为了保持古诗词中字的独立性同时避免分词错误带来影响,选择使用字向量作为模型的输入向量。
特征2:古诗词中地名实体存在同义词和一词多义现象。同义词现象指同一个地点有不同名称,例如南京城又被称为“金陵”、“建康”、“秣陵”、“建邺”等,这一现象在地名命名实体过程中无需特别处理。而一词多义现象指地名除了表示地点外,还有其他含义,如“孝陵”在诗句“台城下接孝陵西”(《故宫行》,明.夏完淳)中代表南京“明孝陵”,而在诗句“孝陵创业三百载”(《金陵望江》,清.黄景仁)中借指明太祖“朱元璋”,可见二者含义差别很大。
一词多义现象是NER任务难点。为尽可能缓解古诗词地点实体识别一词多义问题,本文选择深度学习模型BERT进行预训练,原因在于BERT模型的核心机制Self-Attention可以利用文本中的上下文词语来增强目标词的语义表示,从而区分一词多义现象,但并非代表可以完全解决一词多义问题,具体还需要依靠数据集对模型的训练。
特征3:训练数据集匮乏。古诗词实体识别研究仍处于起步阶段,目前尚未存在完善的古诗词命名实体标注体系,而系统、完整地标注古诗词中的命名实体非短时间内可以完成。囿于研究时间和精力,经过多重筛选、核查与考证,本文最终获得金陵古诗词648首,地名实体1375个,数据集规模不大,使得深度学习模型学习到的实体信息有限。故针对训练语料数据偏少问题,本文将采用实体交叉互换的数据增强方法对已有训练数据进行二次加工,从而扩展古诗词语料库规模。
3.2 模型总体框架设计
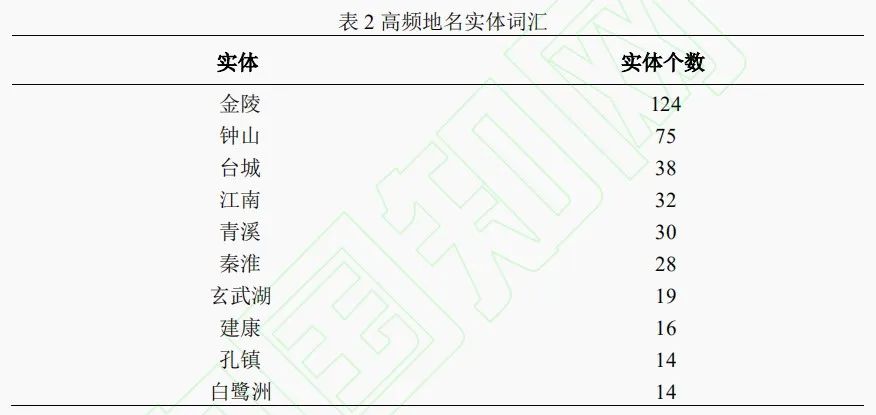
基于上述分析,本文提出由数据增强层DA、预训练层BERT和条件随机场层CRF这三层结构构成的古诗词地名实体识别模型,模型总体框架具体如图1所示。
3.2.1
数据增强层DA
深度学习模型被广泛应用于NER领域,但其效果依赖于数据集规模与质量,数据量不足将容易导致模型训练效果不佳。数据增强是一种有效“数据放大”方法,它通过对已有训练数据进行二次加工,以提升模型训练效果。目前,数据增强已经在图像和语音领域得到广泛应用,例如图像翻转、平移和色彩增强,语音快放与声谱修改等。而在文本数据增强方面,通用方法主要包括词汇替换、句式转换、噪音注入等,但由于文本数据讲究语法结构合理性和通顺性,使得文本增强比较困难,因此基于词表的同义词替换是目前唯一得到广泛应用的方法,其操作简单效果突出,可以较好地丰富实体外部结构。
针对本文所收集的古诗词数据量偏少问题,笔者选择实体交叉替换的数据增强方法。具体为:首先将古诗词按照一定的比例划分为训练集和测试集,然后针对训练集进行数据增强,即将训练集中的某一地名实体随机替换为语料库中另一地名实体,并将替换后的古诗词作为拓展样本复制到原始训练数据集中。只针对训练集进行数据增强是因为考虑到如果在划分数据前对数据集进行增强,那么增强的数据和原始数据会在训练集和测试集中随机分布,导致模型在训练的过程中会接触到不该接触的测试集信息,发生数据泄露,评价指标结果不可信。同时为控制拓展数据和原始数据的差异度,限制每首古诗词中替换的最大实体数为1,其中随机替换实现逻辑如下:将语料库中标注的所有实体以数组的形式进行存储并统计数组长度,最后借用python中random.randint(0,数组长度-1)方法随机返回替换实体的数组下标。
3.2.2
预训练层BERT
BERT模型属于从Transformer中衍生出来的预训练模型,以提取序列全局特征,它采用高性能Transformer结构,可以直接对句子中任何一个字以融合两边信息方式进行编码,并利用遮盖和预测两种方法完成句子词语描述。相较于无法表征词多样性的Word2Vec、GloVe、One-Hot等语言模型,BERT模型利用其Self-Attention结构,可以有效地从不同维度捕获词之间的关联程度,以此实现对当前词更好的编码,因此可以较大程度处理实体在不同语境不同含义的现象,缓解实体识别中的一词多义问题。其在训练过程中,每个序列X={x1,x2,x3,…,xn}以[CLS]标记作为起始Token,以[SEP]作为句子间隔Token,序列对应的输入E={E1,E2,E3,…,En}由三个特征叠加而成,即融合字特征、段特征、位置特征三种特征完成对语料集字级特征向量表示,然后向量E通过全自注意力网络获得序列的丰富语义特征。其模型的输入示例如图2所示。
3.2.3
条件随机场层CRF
CRF模型是解决序列标注问题的经典模型,因为该模型充分考虑了xi对应的标签yi与前后文标注的关系,所以在命名实体识别中运用CRF模型能够很好地约束实体标签,使得字与字之间的标签关系相互依赖。在本研究中,具体约束主要有:地名实体的起始标签为B-Place,I-Place只能出现在B-Place标签后面,E-Place只能出现在B-Place或I-Place标签之后,S-Place只能出现在O标签或者E-Place标签之后。在本文地名实体识别实验中,CRF模型接收BERT层的输出结果后,自动学习诗词序列标签之间的约束,通过计算标签间的转移特征,得到具有最大概率的全局最优标签预测序列。
4 实验结果与讨论分析
4.1环境搭建与参数设置
本文在macOS操作系统中搭建金陵古诗词地名实体识别实验,编程语言为Python,深度学习框架采用Facebook人工智能研究院开发的PyTorch,训练测试采用十折交叉实验法,使用sklearn包中用于交叉验证的KFold函数。所谓十折交叉实验法是将数据集随机划分为10等份,依次取其中的1份作为测试集,另外9份合并作为训练集,循环实验得到10次实验结果。本文通过改变模型中各项参数值并观察测试集识别效果,进行参数优化探索,最终获得模型各项参数如下:
学习率设置:BERT模型在学习新知识过程中可能会遗忘预先训练的知识,而较低的学习率可以使BERT克服灾难性遗忘问题,因此本文根据这一经验以及结合试验将预训练层的学习率设置为0.0001;同时设置参数dropout=0.2,该参数可以在模型训练的过程中随机冻结一部分神经元,因此可以有效防止过拟合;
max_seq_length参数设置:该参数代表模型所能接收的最大序列长度,小于此长度部分将进行padding处理,大于该值的序列则进行截断处理,造成信息丢失,因此结合本文数据集特点和试验结果,设置其值为最大值512;
batch_size参数设置:该参数是影响模型泛化性能的重要参数,大的batch_size可以减少训练时间并提高稳定性,但是同时内存的利用率也会提高,因此本文选择该数据集下实验机器所能允许的最大批次16。其次将epoch参数设置为10,激活函数为“gelu”,优化器为Adamw。
4.2实验结果
本文利用NER任务中通用的精确率(P)、召回率(R)以及调和平均数(F)衡量模型地名实体识别效果。同时为验证本文提出模型的有效性,使用BERT-CRF模型进行实验对比,BERT-CRF模型参数设置同DA-BERT-CRF模型,十折交叉试验结果如表3所示。

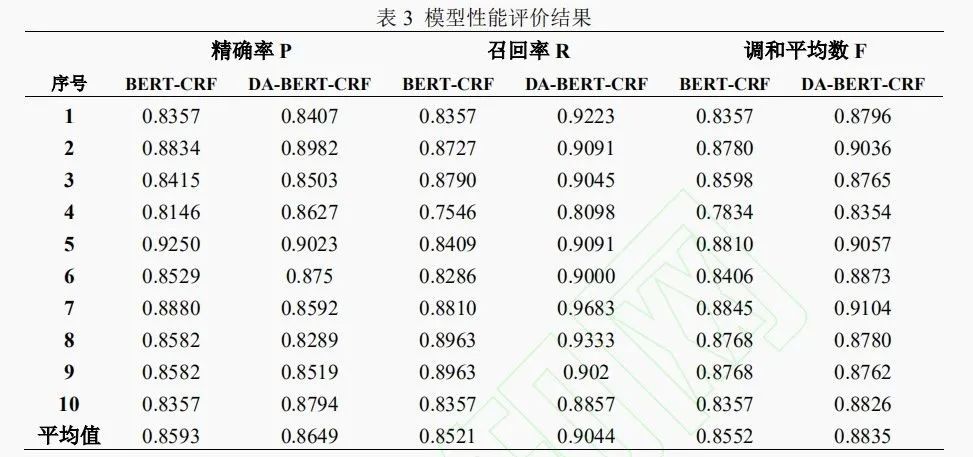
分析上述数据可以发现,DA-BERT-CRF模型识别结果更佳,在十折交叉试验中,平均精确率、平均召回率、平均调和平均数均得到提升,分别达到86.49%、90.44%、88.35%,进一步分析实验结果可以发现:
(1)在数据集处理上,引入数据增强方法能够显著提升模型地名实体识别效果。试验结果显示,数据增强后的BERT-CRF模型其精确率提升了0.55%,召回率提升了5.23%,调和平均数提升了2.83%,这是由于深度学习模型在处理实体识别任务时需要大量标注数据来训练模型,如果训练数据较少,其训练可能不够充分,而采用实体交叉互换的数据增强策略可以在扩充语料库的同时丰富地名实体的外部结构,因此可以有效减少小样本下的实体漏检情况发生,提高对单字实体以及罕见地名实体的识别率,同时也可以缓解实体边界模糊现象。例如诗词《南朝》(唐.李商隐)中诗句“鸡鸣埭口绣襦回”中存在地点实体“鸡鸣埭”,DA-BERT-CRF模型将其识别正确,而BERT-CRF模型则识别为“鸡鸣”,又如《次韵赠清凉长老》(宋.苏轼)中诗句“过淮入洛地多尘”中“淮”和“洛”均属于单字地点实体,模型在经过数据增强后,丰富了这两个实体的外部结构,提升了单字地名识别准确率,诗词《暮春与诸同僚登钟山望牛首》(宋.苏颂)中诗句“乘兴游北钟”中“北钟”,其代表地点实体“钟山”,“北钟”在语料库中仅出现一次,但是DA-BERT-CRF模型将其成功识别,而BERT-CRF模型则识别失败,同时像“白鹭”、“姑熟”、“汤碧山”、“宝公塔”这类语料库罕见地名,通过数据增强后模型也可以准确将其识别。
(2)在模型选择上,引入BERT算法可以有效缓解一词多义的问题。BERT预训练层在表达古诗词上下文语义特征上具有优势,如前文提到的诗词“孝陵创业三百载”中“孝陵”二字借指人物“朱元璋”,而非地点“明孝陵”,分析该句的模型识别结果,发现DA-BERT-CRF模型可以正确处理这种情况。值得注意的是,诗词《金陵乌衣园》(宋.吴潜)中诗句“乌衣巷,今犹在。乌衣事,今难觅。”中第一个“乌衣”代表南京市秦淮区的一个古巷,属于地点实体,而第二个“乌衣”指穿黑衣的差役,并非指代地名。在本文实验中,BERT-CRF模型错误地将第二个“乌衣”识别为地点实体,而DA-BERT-CRF模型则识别正确,这在一定程度上说明,一词多义问题的解决需要依靠数据集对模型进行训练,数据集越大模型训练的越充分,那么模型在理解文本语义上则更具优势。此外,本文通过引入CRF模型改善了实体标签预测结果,使得E标签后紧跟E标签这类不合理预测明显减少,进一步提升了地名识别效果。
5 结语
古诗词地名书写着华夏历史,承载着家国情怀。古诗词地名实体识别不仅对于深入理解与分析古诗词作品含义具有重要学术价值,而且对于理解我国历史建筑、历史名城的独特文化内涵具有重要实践意义。本文以金陵古诗词为研究对象,紧紧围绕地名实体识别这一研究主题进行实体识别研究,针对古诗词标注数据集规模小、存在单字地名实体、一词多义等问题,提出DA-BERT-CRF模型。研究结果表明,该模型能够较好地处理一词多义问题,并有效解决小样本情况下命名实体识别问题。在后续研究中,为提升模型地名识别性能,计划从以下两个方面进行探索与突破:一是加强金陵古诗词地名标注语料库建设,主要包括提升数据源的丰富性、人工标注的准确性以及标注规则的合理性,避免漏标、误标情况发生;二是加强古诗词地名实体识别模型建设,主要包括字词特征挖掘、模型参数优化、深度学习网络结构设计与改进等。
作者:余馨玲 常娥
来源:《图书馆杂志》2022年
选稿:耿 曈
编辑:邹怡思
校对:黎淑琪
审订:黄海红
责编:黄舒馨







